by Daniel S. Katz and Kenton McHenry
We typically think of Research Software Engineers (RSEs) as working to support one or more researchers, either one-on-one or through a university’s centralised RSE group. We’ll call this the traditional RSE role, while being fully aware how ironic this phrase is. Simon Hettrick has used the following image, where “Here” indicates where the RSE fits between software engineering and research.

However, the idea of a single dimension for a software engineer, RSE, researcher/developer, and researcher seems limiting, and perhaps there are other ways of looking at this that add something. If we think of software engineering and research (in a discipline) as two dimensions, we come up with this view of where an RSE fits:

And once we have done this, we can also consider that different universities have different organizations under which RSEs work. In practice, at least at NCSA, many of our developers both work with and support researchers, and also work in teams of RSEs who research and develop their own software, support it, grow it, sustain it, etc. We’ll call this a Super RSE role, since it includes a superset of the responsibilities of the traditional RSE role, combining both service and the RSE’s own research. We need to add a dimension to the figure for this, as shown below. This secondary research area, often a complementary area (e.g., in sub-areas of Computer Science, Information Science, etc), that adds more to the effort through capabilities, novelty, and/or an extended community.
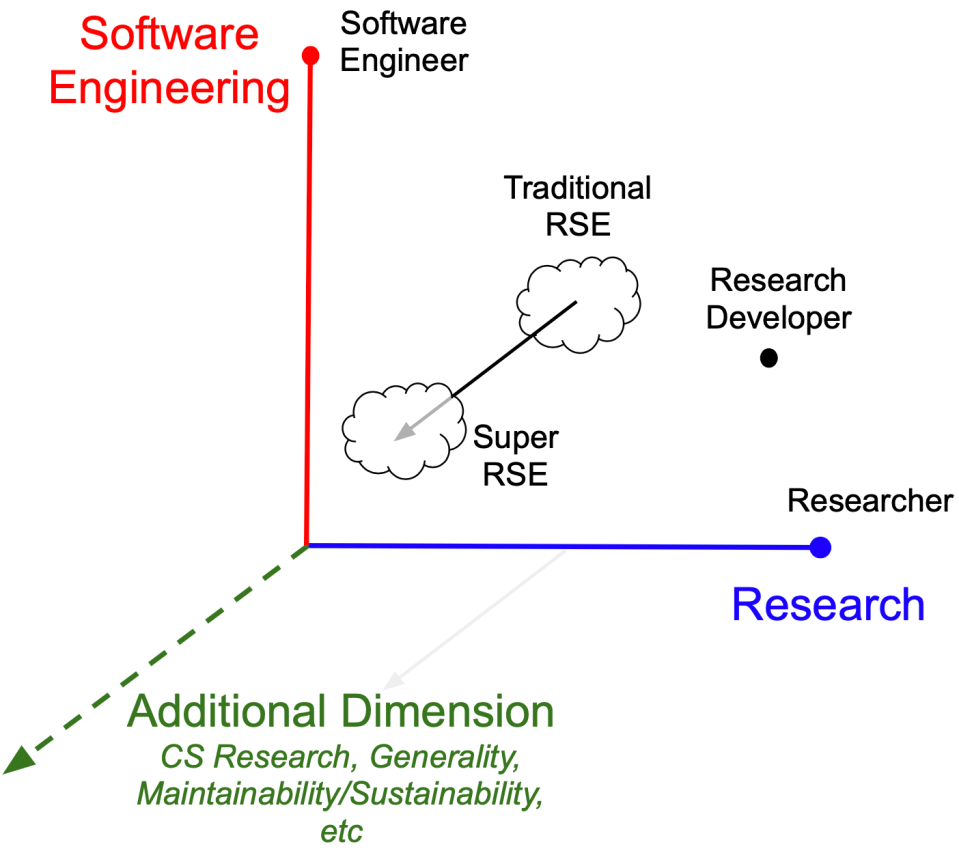
We believe that it’s important to include this Super RSE role in a group, because this is where the core technologies that no one researcher wants to support live and thrive, and these technologies, as much as the skills of the RSEs, are what distinguishes that RSE group from all the others. They are also what the RSE group “owns” and take pride in, in addition to the things they enable but don’t own.
We believe this idea of a Super RSE role attracts a set of researcher-developers to NCSA who might not be interested in a more traditional RSE role. The in-house software also serves as a leverageable artifact from a project that can be used to help us win new projects with our collaborators; ramp up projects quickly, giving them something on Day 1; and allow collaborators to get more bang for their buck as other projects develop features they can then leverage. In addition to this directly making us stronger externally, it also allows us to make a stronger case to the university for institutional support than just supporting researchers would, because it creates an increased return on investment.
This leads to an ongoing discussion of where the boundaries of RSE should be set, if there should be boundaries. In order to have the term be useful, it likely needs some boundaries. The US-RSE group says “We like an inclusive definition of Research Software Engineers to encompass those who regularly use expertise in programming to advance research. This includes researchers who spend a significant amount of time programming, full-time software engineers writing code to solve research problems, and those somewhere in-between. We aspire to apply the skills and practices of software development to research to create more robust, manageable, and sustainable research software.” The UK RSE group says “Research Software Engineers are people in a variety of roles who understand and care about both good software and good research. It is an inclusive definition that covers a wide spectrum of people …”
We hope that this concept of Super RSEs will be useful in setting the boundaries of RSEs and perhaps in defining a portion of the RSE space. And we recognize that Super RSEs might not be the final term for this kind of work, as it might be seen as implying that other parts of the RSE space are less super, which is not our intention.

There is a typo in the Additional dimension part of the figure: “Generalility”.
Thematic (disciplinary) research is sometimes distinguished from more methods based research. Methods developed for research in one discipline/field are often useful in others. Generalising methods and making them more easily applied in other disciplinary contexts for empirical research is often key to major advances in understanding.
I was in a meeting recently where a colleague said that they had stopped trying to bust the RSE acronym as it was perhaps best left being a bit ambiguous. I am not thinking that attempts to define RSE and details roles are unhelpful, but I do think that it is helpful to consider these as fuzzy and that sometimes ambiguity is useful.
LikeLike
Thanks Andy – I’ve fixed the typo (I hope)
LikeLike
It is fixed 🙂 There is a double t in Simon’s surname.
LikeLike
thanks again
LikeLiked by 2 people
I really appreciate this post, thank you. I am writing about research software engineering practices in my doctorate, and need to define the terms I use.
In the paper I just submitted, I used the term Super RSE. Now that I’m writing a follow-up, I’m thinking, what about, intead of Super RSE, we use the term metaresearch software engineer? MSE? Or MRSE? I’m on the fence about the intitialism.
I’m writing this paper right now, opened an issue on it here: https://github.com/softloud/codeproof/issues/2
just in case you had thoughts.
Thanks, again, for a great post!
LikeLike
I’m sure this isn’t the best name, but I don’t know what is better, or if a name is really needed. I think the more important thing is the recognition of the different types of work and different foci that fit under research software engineering.
LikeLike